Migrating your Home Assistant database from SQLite to PostgreSQL can significantly enhance performance, especially as your data grows. This guide will walk you through creating a database dump, converting data types, setting up your PostgreSQL database, and configuring Home Assistant to use the new database.
Creating the Database Dump from SQLite
To start, you need to create a dump of your existing SQLite database:
sqlite3 home-assistant_v2.db .dump > ha_dump.sql
This command creates a plain text file containing the SQL commands needed to reconstruct the database.
Converting Data Types
During the migration from SQLite to PostgreSQL, certain data types need to be converted:
DATETIME to TIMESTAMP: PostgreSQL uses TIMESTAMP instead of DATETIME.
sed -i 's/DATETIME/TIMESTAMP/g' ha_dump.sql
BLOB to BYTEA: Convert BLOB fields to BYTEA for binary data.
sed -i 's/BLOB/BYTEA/g' ha_dump.sql
Preparing PostgreSQL Database
Creating Database and User
Start by setting up your PostgreSQL database and user:
CREATEDATABASE homeassistant;CREATEUSER ha WITH ENCRYPTED PASSWORD 'yourpassword';GRANTALLPRIVILEGESONDATABASE homeassistant TO ha;
Create the objects and load the data
Use the command line utility psql to create the database objects and load the data into the newly created PostgreSQL database:
Replace [your_db_host] with the actual hostname or IP address where your PostgreSQL database is hosted.
User and Database: Ensure that ha is the correct username and homeassistant is the correct database name you created for Home Assistant.
After running the command, the SQL dump file (ha_dump.sql) will be executed against your PostgreSQL database. The output and any errors encountered during the process will be redirected to load.log. This log file is essential for tracking the progress and identifying any issues that need resolution.
Check for Errors:
Review the load.log file for possible errors. This file contains all output from the psql command, including any SQL errors or warnings that were generated during the import process.
Iterate as Necessary: If errors are found, you may need to fix issues in ha_dump.sql and rerun the command. This step might need to be repeated several times. Modifications could involve correcting data types, adding missing sequences for auto-incrementing fields, or adjusting SQL syntax to be compatible with PostgreSQL.
This process can be time-consuming, but it is crucial for ensuring that your database is correctly set up with all the necessary data and schema configurations. As noted, your mileage may vary depending on the specifics of your data and the initial state of the ha_dump.sql file.
Adjusting the Schema
For tables needing auto-increment functionality (which is common in primary key columns), set up sequences:
CREATE SEQUENCE states_state_id_seq;ALTERTABLE states ALTERCOLUMN state_id SETDEFAULT nextval('states_state_id_seq');SELECT setval('states_state_id_seq',(SELECTMAX(state_id)FROM states)+1);
Repeat this pattern for other necessary tables and columns, such as events(event_id), state_attributes(attributes_id), and so on.
Configuring Home Assistant
Install SQLAlchemy and other dependencies
Home Assistant uses SQLAlchemy as the SQL toolkit and Object-Relational Mapping(ORM)system for Python. Install it with pip:
This setup directs Home Assistant to use the newly configured PostgreSQL database.
Benefits of Migrating to PostgreSQL
Moving from SQLite to PostgreSQL offers several benefits:
Scalability: PostgreSQL handles larger databases and more concurrent connections.
Performance: Improved query performance and optimization options.
Reliability: Robust transaction support and recovery features.
Flexibility: Richer set of data types and full-text searching capabilities.
Conclusion
Migrating your Home Assistant database to PostgreSQL not only enhances performance but also provides a more robust and scalable backend, suitable for growing smart home environments. This migration ensures that your Home Assistant setup can handle increased data loads efficiently and reliably.
Famous last words
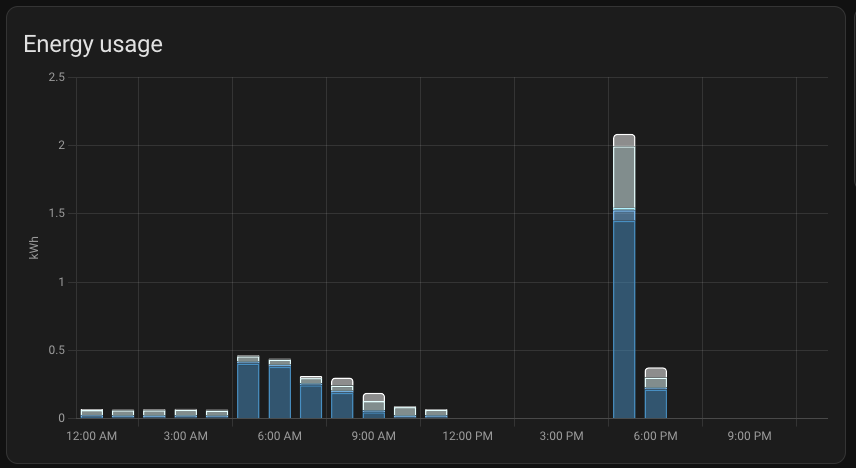
One of my primary concerns during this migration was the potential loss of historical data, particularly how it might affect critical metrics like energy usage. The statistics table, which was the last to have the auto-incremental column added, is pivotal as it houses the energy usage stats.
As the image below shows, there appears to be a gap of approximately four hours in the data on energy usage stats. However, it seems that Home Assistant has effectively compensated for this missing data. The system appears to have aggregated the missing energy usage from those four hours into the data represented in the 5 PM bar on the chart.
This outcome is quite reassuring and confirms that the system’s integrity remains intact despite the migration hiccups. I’m relieved to see that after all the adjustments and troubleshooting, everything is functioning as expected.
This experience underscores the importance of careful planning and execution in database migrations, especially when dealing with essential home automation systems like Home Assistant. The transition may require significant effort and attention to detail, but the end result can be gratifying, ensuring continuity and robustness in data handling.
A self-built AI chatbot is crafted entirely by an individual or team from scratch, without relying on pre-existing templates or platforms. This approach gives developers complete autonomy over the coding, features, and functionalities of the chatbot.
Creating a self-built AI chatbot demands a blend of programming expertise, a deep understanding of artificial intelligence, and inventive thinking. Developers can use a variety of programming languages, including Python, Java, or JavaScript, based on their preferences and the chatbot’s intended application.
One of the standout advantages of a self-built AI chatbot is its high level of customization. Developers can fine-tune the chatbot’s responses and functionalities to meet specific needs and objectives. Moreover, they can continually refine and enhance the chatbot on their own timetable, independent of external updates or support.
Getting started
Building a chatbot from scratch might seem daunting, but it’s quite feasible with the right tools. I used the OpenAI API and the Python openai library (version 1.23.2 as of this writing). While GPT-4 typically suggests using openai==0.28, the transition to versions above 1.0 signifies substantial changes and necessitates thoughtful consideration. However, this doesn’t mean that ChatGPT cannot assist in coding—it can, though it requires precise instructions.
Technical setup
For my project, the technical foundation included:
Python 3.9.x or higher: I chose Flask as the application server.
Access to the OpenAI API: Essential for integrating the AI logic into the chatbot
This setup is sufficient to establish a testing environment for the AI logic, connecting the Python code to the OpenAI API.
Advanced configuration
After thorough testing, I moved on to production. I continued using Flask for its simplicity, but also added Gunicorn as a frontend server. The application runs either as a standalone version or embedded within a WordPress blog.
I explored different operational models, including storing interactions in a database and the Bring Your Own Data (BYOD) model, although the latter’s impact on performance is still unclear. Initially, I deployed the gpt-3.5-turbo-instruct model for its speed and contextual retention. However, for superior output quality, I ultimately chose GPT-4 despite its slower response time.
The AI Bot Herself
The embedded ChatBot is utilizing gpt-3.5-turbo-instruct whereas the one on below links is utilizing gpt-4 model. The later needs a bit time to think, but she will get there… You can compare the results.
Conclusions
A self-built AI chatbot can serve myriad purposes—customer support, entertainment, educational assistance, or personal aid, and can be integrated across websites, messaging platforms, or mobile apps.
For me, the project was primarily an exploration of AI technologies and the OpenAI API. It was also an invaluable learning experience in Python, application servers, and container technologies.
Building a self-built AI chatbot is undoubtedly a complex, resource-intensive endeavor that necessitates ongoing updates and maintenance. Yet, the potential for continuous learning and improvement through natural language processing and machine learning algorithms makes it increasingly efficient and precise over time.
From a Friday morning start to a productive Monday evening, my journey with this project underscores the potential and versatility of AI technologies, making a self-built AI chatbot a potent, customizable tool for any tech-driven initiative.
Securing your HomeAssistant setup should be a priority, especially if you plan on accessing your system remotely. One of the best ways to do this is by setting up an SSL certificate. This article guides you through five easy steps to set up SSL on HomeAssistant using Let’s EncryptCertbot.
Understanding the Importance of SSL for HomeAssistant
Secure Sockets Layer, popularly known as SSL, is a security protocol that encrypts the connection between a web server and a client. When implemented on your HomeAssistant, it prevents eavesdropping and tampering of your data by encrypting all communication between your HomeAssistant and your devices. This is crucial, especially when accessing your HomeAssistant remotely over the internet where your data could be intercepted.
Moreover, SSL also provides authentication, ensuring that you’re communicating with the right server and not a malicious one. This is achieved through the use of SSL certificates issued by trusted Certificate Authorities (CAs). These certificates also provide visual cues, such as a padlock symbol, giving end-users confidence that their connection is secure.
An Overview of Let’s Encrypt Certbot
Let’s Encrypt is a free, automated, and open Certificate Authority. It provides digital certificates needed to enable HTTPS (SSL/TLS) for websites. The Certbot is an easy-to-use client that fetches certificates from Let’s Encrypt and configures your web server to use them.
By using Let’s Encrypt Certbot, you can easily acquire and renew SSL certificates for your HomeAssistant. It automates the process of obtaining and installing SSL certificates, thereby saving time and eliminating the risk of manual errors. Moreover, it also handles the renewal of SSL certificates, ensuring that your connection remains secure.
Contrary to what seems to be the case for many, if not most, I find the use of third-party VPN solutions for accessing an otherwise cloud-free HomeAssistant setup to be illogical. Moreover, the notion of implementing the HomeAssistant Cloud service, Nabucasa, doesn’t appeal to me at all. The core of my philosophy is to maintain a smart home solution that is independent of both third-party and cloud services.
Step 1: Installing Let’s Encrypt Certbot
The initial step to enable SSL for your HomeAssistant involves installing Let’s Encrypt’s Certbot. The installation method differs across operating systems. On Linux systems, it’s straightforward to install Certbot using the package manager. For example, Ubuntu users can execute the command sudo apt-get install certbot.
My setup took a slightly different route. As previously mentioned, my HomeAssistant operates within a Docker container, and I also host several websites, including the one hosting this blog post, on a virtual machine. This VM shares the same server as the HomeAssistant Docker container. Installing Certbot on CentOS Stream, the operating system of my VM where SSL is primarily needed, was a breeze by simply following the guided instructions available on the Certbot website.
You can confirm the successful installation of Certbot by executing certbot --version in your terminal. This command should return the version number of Certbot installed on your machine. Should you encounter any issues, indicating that Certbot hasn’t been installed properly, you may need to address the installation process or attempt reinstalling it.
Step 2: Generating an SSL Certificate
With Certbot installed, the subsequent step involves generating an SSL certificate for your domains. In my experience, executing the command certbot --apache was a straightforward process. Certbot intelligently scanned all my Apache virtual hosts, generating certificates for each. Interestingly, it selected the first domain in the list as the root certificate for all others—a decision I wouldn’t have made intentionally, but one I’m content with nonetheless.
Aiming to secure a certificate for HomeAssistant as well, I introduced fake virtual hosts within Apache and initiated certbot --apache once more, this time specifying the addition of the exclusive HomeAssistant domain, which for me is ha.auroranrunner.com.
An alternative method involves the command certbot certonly --standalone. This approach instructs Certbot to secure a certificate by functioning as a temporary web server (standalone) to authenticate domain ownership—useful for situations requiring a more hands-off approach.
However, my objective was for Certbot to manage the certification updates for all domains collectively, thus I adopted a slightly different strategy.
Opting to exclusively focus on HomeAssistant, without intertwining Apache configurations, prompts a straightforward process. You’ll be asked to input your domain name along with your contact details. Upon submission, Certbot seamlessly liaises with the Let’s Encrypt Certificate Authority (CA), generating an SSL certificate for your domain. The newly minted certificate and its private key are securely stored in the directory /etc/letsencrypt/live/your_domain_name/.
Step 3: Setting SSL sync between primary host and secondary host
In my situation, it was necessary to establish a method for synchronizing the SSL certificates between the virtual machine hosting the Apache web servers and the server operating the HomeAssistant Docker container. To accomplish this, I undertook the following steps:
Established passwordless SSH authentication between my Apache hosts and the server hosting HomeAssistant to ensure a seamless connection.
Created a script located at /usr/local/bin/sync_lets_cert designed to facilitate the synchronization of Let’s Encrypt certificates.
Developed a systemd service aimed at automating the daily synchronization of Let’s Encrypt certificates between the two hosts, ensuring that both systems always use the latest SSL certificates.
Configured a dedicated volume for the HomeAssistant Docker container mapped to /etc/letsencrypt:/etc/letsencrypt. This setup allows the HomeAssistant container direct access to the synchronized SSL certificates, simplifying the process of securing communications.
The script located at /usr/local/bin/sync_lets_cert is responsible for synchronizing the SSL certificates between servers. Its contents are as follows:
#!/bin/bash# Variables
SECONDARY_SERVER="my_vm_host_server"
DOMAIN="ha.auroranrunner.com"
LIVE_PATH="/etc/letsencrypt/live/$DOMAIN"
ARCHIVE_PATH="/etc/letsencrypt/archive/$DOMAIN"
DEST_LIVE_PATH="/etc/letsencrypt/live/$DOMAIN"
DEST_ARCHIVE_PATH="/etc/letsencrypt/archive/$DOMAIN"# Sync the live directoryrsync -avz -e ssh$LIVE_PATH/ $SECONDARY_SERVER:$DEST_LIVE_PATH# Sync the archive directoryrsync -avz -e ssh$ARCHIVE_PATH/ $SECONDARY_SERVER:$DEST_ARCHIVE_PATH
This script ensures that the certification files are kept in sync between the hosts. The next step involves setting up a systemd service to schedule this script’s execution, which proved to be slightly more complex but was successfully achieved as follows:
Create a timer file at /etc/systemd/system/sync_lets_cert.timer with the following content to establish a daily execution schedule:
With these steps completed, the SSL certificates will not only be renewed every 90 days but also synchronized between servers daily, ensuring seamless security and authentication continuity.
Step 4: Setting up SSL on HomeAssistant
With the SSL certificate secured, the following step is to integrate SSL into your HomeAssistant setup. This process entails adjusting your HomeAssistant’s configuration to recognize and utilize the SSL certificate. Achieve this by appending the below entries into your HomeAssistant’s configuration.yaml file:
These lines instruct HomeAssistant on the locations of the SSL certificate (fullchain.pem) and its corresponding private key (privkey.pem). Post addition, a restart of your HomeAssistant is required for the adjustments to be applied.
Initially, setting up SSL without specifying base_url sufficed for web browser access. However, to ensure the mobile application functioned correctly, including the base_url became necessary.
Regarding domain registration, I own auroranrunner.com and manage its DNS settings via the AWS console. Given the dynamic nature of my IP address, I employ the dy.fi service to update the DNS record for my dy.fi domain automatically. On AWS Route 53, ha.auroranrunner.com is configured with a CNAME record pointing to sirius.dy.fi, a nifty setup. Thanks to my router’s dy.fi support, any alterations to my external IP are automatically synchronized.
Step 5: Troubleshooting Common SSL Setup Issues
While setting up SSL on HomeAssistant using Let’s Encrypt Certbot is straightforward, you might encounter some issues along the way. One common issue is the “Failed authorization procedure” error. This usually occurs when Certbot is unable to verify domain ownership. To resolve this, you need to ensure that your domain name is correctly pointed to your HomeAssistant’s IP address.
Another common issue is the “SSL connection error”. This usually occurs when HomeAssistant is not correctly configured to use the SSL certificate. To resolve this, you need to ensure that the paths to the SSL certificate and its corresponding private key in your HomeAssistant configuration file are correct.
Setting up SSL on HomeAssistant using Let’s Encrypt Certbot is a good way to secure your system. While the process might seem complex, it can be broken down into five easy steps: installing Certbot, generating an SSL certificate, setting up SSL on HomeAssistant, configuring HomeAssistant with the SSL certificate, and troubleshooting common SSL setup issues. By following these steps, you can secure your HomeAssistant and ensure that your data remains safe and private.
Conclusion
Implementing SSL with Certbot is relatively straightforward for those who are well-acquainted with their network setup. This approach offers a security advantage over depending on third-party VPN solutions, which merely introduce an additional layer to your existing infrastructure. Leveraging third-party services to manage your smart home system does not enhance security; rather, it compromises it. While VPNs can serve as a viable security measure for those lacking the expertise to properly configure their home networks, the assertion that third-party VPNs inherently bolster security is misleading.
For those considering a VPN, I advocate for hosting your own. In my experience, OpenVPN has been fully compatible with HomeAssistant, offering a cost-effective solution without the need for extra expenditures. Like the SSL setup, OpenVPN requires dynamic DNS unless you have the luxury of a static IP address, ensuring reliable and secure remote access to your smart home systems.
Database migration is a complex process that demands careful assessment to ensure data integrity, application performance, and overall system reliability. The OpenAI API, with its advanced natural language processing capabilities, offers a way to simplify this process by automating assessments and summarizing key points. This guide will walk you through using the AWS Schema Conversion Tool (AWS SCT) for initial assessments, integrating the OpenAI API with Python to generate assessment summaries, and understanding the requirements for connecting with Azure OpenAI API, as well as its differences from ChatGPT OpenAI.
Kickstarting Your Migration: Utilizing AWS SCT for Comprehensive Database Assessment
The Amazon Web Services Schema Conversion Tool (AWS SCT) simplifies database migration from one platform to another. It assesses your existing database schema and generates a detailed report on potential migration issues. Supporting a wide range of source and target databases, AWS SCT is versatile for many migration scenarios.
AWS SCT examines your database schema, identifies non-convertible elements, and produces a comprehensive report. This report, containing potential action items, is crucial for planning your migration, offering an overview of the complexity, potential challenges, and the effort required.
The report, in PDF format, provides a detailed view of your database schema, potential issues, and recommendations. While invaluable for database administrators and engineers, the report’s extensive and complex nature makes OpenAI API a perfect tool for simplification and summarization.
Transforming PDFs into Comprehensive Assessment Summaries
With the AWS SCT report in hand, the next step is to utilize OpenAI API’s sophisticated natural language processing capabilities. By reading and understanding the PDF report, OpenAI can extract key points and summarize the information in a more accessible format.
Using the Python package pymupdf, we scan the PDF and convert its contents to text. This text is then fed to OpenAI API to highlight important sections and summarize the findings, including potential issues and recommended actions.
The Python method process_directory reads each PDF, converts it to text, and then passes this text to another method, generate_summary, which calls the OpenAI API to generate a concise assessment summary.
Method: process_directory()
defprocess_directory(directory):"""Processes each PDF file in the given directory to generate a summary."""
hostname, port_number, database_name = directory.split('_')forfilein os.listdir(directory):iffile.endswith('.pdf'):
file_path = os.path.join(directory,file)
pdf_text = extract_text_from_pdf(file_path)
summary = generate_summary(pdf_text)print(f"Summary for {file} ({hostname}, {port_number}, {database_name}):\n{summary}\n")
Method: generate_summary()
defgenerate_summary(text):"""Generates a summary for the given text using OpenAI's API."""
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role":"system","content": "You are database \
reliability engineer providing migration \
assessment summary."},{"role":"user","content": "Summarise the output \
of assessment text: \n" + text}],
temperature=0.4,
max_tokens=150,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0)
summary = response.choices[0].message.content.strip()return summary
Understanding OpenAI API Parameters
Understanding the role and impact of various OpenAI API parameters is crucial for tailoring your query results. Here’s a brief overview:
temperature (0.4): This parameter controls the level of creativity or randomness in the responses generated by the model. A lower temperature, such as 0.4, results in more predictable and conservative outputs. Conversely, a higher temperature encourages diversity and creativity in the answers.
max_tokens (150): Specifies the maximum length of the generated response measured in tokens (words and characters). Setting this to 150 means the response will not exceed 150 tokens, ensuring concise and to-the-point answers.
top_p (1.0): Also known as “nucleus sampling,” this parameter filters the model’s token generation process. A value of 1.0 means no filtering is applied, allowing any token to be considered. Lowering this value helps in focusing the response generation on more likely token sequences, potentially enhancing relevance and coherence.
frequency_penalty (0.0): Adjusts the likelihood of the model repeating the same line of text. A value of 0.0 implies no penalty on repetition, enabling the model to freely reuse tokens. Increasing this value discourages repetition, fostering more varied and dynamic outputs.
Above python methods generated modest summary from my sandbox environment. Modest at this point – we can take this much further though. I’ve taken small part of whole summary describing migration effort from MS SQL Server 2019 database to RDS for PostgreSQL.
Migration Plan Summary
Source Database
AdventureWorks2019.MSSQL
Microsoft SQL Server 2019 (RTM-CU22-GDR) – 15.0.4326.1 (X64)
Standard Edition (64-bit) on Windows Server 2019 Datacenter
Case sensitivity: OFF
Target Platform:
AWS RDS for PostgreSQL
Assessment Findings:
Storage Objects: 100% can be converted automatically or with minimal changes.
Code Objects: 77% can be converted automatically or with minimal changes.
Estimated 99.9% of code can be converted to AWS RDS for PostgreSQL automatically.
515 conversion actions recommended ranging from simple to complex tasks
OPENAI
Above AI-generated summary can be a significant time saver for database administrators and engineers. Instead of going through pages of detailed reports, they can quickly glance through the summary and understand the key points. It can also be used as a reference guide during the migration process, helping to avoid potential issues and ensuring a smooth transition.
Building a fully automated OpenAI-Powered Python Module for PDF Analysis and Summary Generation
To generate the assessment summary using the OpenAI API, I developed the Python methods described above. These methods are components of a larger assessment framework that I’m currently developing. In this article, we focus exclusively on the integration with the OpenAI API. It’s worth noting that the PDF files used as input are generated through a fully automated process. However, the details of that process are beyond the scope of this blog post.
Python, with its versatility and powerful capabilities, is ideal for integrating with the OpenAI API. It offers libraries for API interactions and processing PDF files, enabling the automation of the entire workflow—from reading PDF files to generating summaries.
For the initial step, libraries such as PyPDF2, PDFMiner, or pymupdf—which I prefer—can be utilized to read the contents of PDF files. After extracting the text, this information can be processed by the OpenAI API. The API is designed to analyze the text, pinpoint the essential information, and compile a concise summary.
Subsequently, this summary can be saved either as a text file or within a database for easy access in the future. Moreover, the module can be configured to insert summaries into a database table, integrating them into a larger assessment data repository. This data can then be leveraged for generating reports, such as Power BI dashboards or other forms of reporting, allowing key stakeholders to stay informed about the migration process’s progress.
Setting Up Azure OpenAI API: Essentials and Differences from ChatGPT
The Azure OpenAI API is a cloud-based service enabling developers to integrate OpenAI’s capabilities into their applications. To utilize the Azure OpenAI API, one must have an Azure account and subscribe to the OpenAI service, in addition to generating an API key for authentication during API requests.
There are notable differences between utilizing ChatGPT and the Azure OpenAI API.
For ChatGPT, your Python module only requires the openai.api_key to be set, along with specifying the model, such as “gpt-4” in my example code. However, integrating with the Azure OpenAI API necessitates additional configuration:
It’s important to note that when using Azure OpenAI, Python OpenAI API parameter model corresponds to your specific deployment name instead of “gpt-4” as it was for ChatGPT model in my examples earlier.
The Azure OpenAI API and ChatGPT OpenAI both offer advanced natural language processing capabilities, albeit tailored to different use cases. The Azure OpenAI API is specifically designed for embedding AI functionalities into applications, whereas ChatGPT OpenAI excels in conversational AI, facilitating human-like text interactions within applications.
Choosing between the two for summarizing database migration assessments hinges on your project’s unique needs. Azure OpenAI API is the preferable option for projects requiring deep AI integration. On the other hand, if your application benefits from conversational AI features, ChatGPT OpenAI is the way to go.
In summary, utilizing the OpenAI API can drastically streamline the database migration assessment process. The AWS Schema Conversion Tool yields a thorough report on your database schema and potential issues, which can efficiently be condensed using the OpenAI API. By developing a Python module, this summarization process becomes automated, thus conserving both time and resources. Regardless of whether Azure OpenAI API or ChatGPT OpenAI is chosen, each offers potent AI capabilities to facilitate your database migration endeavors.
Finland has been part of Nord Pool, a pan-European power exchange, since 1998. Meaning, when you sign your power contract with electricity supplier, you can choose a contract utilising the power stock exchange prices.
The prices for the next day are announced every day around 1pm CET. You can combine this information for example with weather forecast to plan your electricity usage for the cheapest hours where applicable.
Home Assistant on the other hand has Nord Pool integration which enables you to optimise the electricity SPOT pricing. There is a lot of articles on how to do that to help you to get started. This articles goes through my current setup and my own experience with both Home Assistant and electricity stock pricing. And how I made everything working with GitHub Copilot vim plugin.
Typical claim is, that normal user cannot really utilise the power stock pricing since it is too much work, warming up the house takes constant amount of energy so there is no way to optimise or it is too much work to do the automation in he first place. The latter might be true, but if you take building a smart home as a hobby, then even that is not true. The more time it takes, the more fun it is.
Home Assistant is a hobby anyway. It’s non commercial product and it is Cloud independent: Meaning, you set it your yourself and you maintain it yourself in your own server. That being said, it is fairly easy to set up. You just need to have a server to install it. That can be dedicated server or mini computer like Raspberry Pi, old PC you have no other use or something that can run Linux.
My choice was to to use my Asus PN41 mini PC I already had running Ubuntu which I had set up earlier to run as my sandbox having several virtual machines running in it. Instead of adding another virtual machine I decided to setup Home Assistant as Docker Container. Installation and set up did not really take too long time. Once I installed mobile app to my phone I already had working setup.
The reason why I wanted to have Home Assistant in the first place though is, that I had two Toshiba Shorai Edge heat pump internal units installed, and Toshiba’s mobile app is installable only with European apple id. I have North American apple id and I really cannot change that, since although living most of the time in Europe, I have close ties to North America. After some googling I figured out that I can get around the limitation with this totally new thing for me at the time called Home Assistant.
After I had Home Assistant container running, Toshiba AC integration installed and mobile app on my phone, I was good to go. Setup up is really fast to do as long as one is familiar with the related technology it really doesn’t take more than an hour. My initial aim was just to be able to manage the internal heating units through my phone. Then later I noticed that ok, it is also much easier, for example, to schedule the heat pumps to different temperatures different times with Home Assistant than with extremely cumbersome Toshiba remote.
On the other hand, I noticed Home Assistant itself had plenty of other interesting features I could utilise while building a smart home gradually. I got four Shelly H&T and one Shelly Plus H&T thermometers I could have on my Home Assistant dashboard. Three Shelly Plugs to monitor electricity usage for the Heat Pump and other appliances.
Automation
Just having Home Assistant Mobile App running enabled me being able to control heat pump units, follow room temperatures, current weather and forecast, electricity consumption and price is of course nice, but everything is still done manually. I felt I’m missing at least half of the benefits and nothing really changed anything yet.
Then I found this blog post on how to automate device for cheapest hours and it was pretty much all I was looking for. At least on idea level it was. It grabs the next days cheapest electricity prices and one can schedule heat pump to increase temperature when the electricity is on it’s cheapest. This happens typically at night – it is just after midnight almost always. I wasn’t very familiar with yaml and I still find the syntax cumbersome to get anything working – anything working easily at least. There’s plenty of scheduling solution with GUI based forms, but for me understanding those was even more difficult. I got this solution for getting next day’s cheapest hours and increase heating during them to work fine except for one thing. Once it started, it did not stop without manually stopping it.
I decided to create a schedule which set the heating back from 24C to 20C at 5am. With Home Assistant of course. If the cheapest hours are at day time, that does not work though. But it worked well enough almost for a year. Then I got more involved with yaml while learning Ansible and writing Pipelines for Azure with yaml. I also utilised yaml syntax highlighting on vim, so it all started to get easier.
Why write own code when there’s Github Copilot
Completing the first idea
The biggest motivator I found was Github Copilot. I started to use it while writing Python code, but noticed it helps quite a lot with yaml too. I only wanted to change my automations.yaml slightly. I wanted to get the part working, where the heating should stop. And I don’t want any heating blowing full 24C during day time either. Copilot does not write it to you, but it makes it easier to get it done.
So I did this: added the time conditions with after and before.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Set temp to 24C when the SPOT price is at it's cheapest.
- id:'1663399614818'
alias:Increase heating
description:'Cheap energy time set heating to 24C'
trigger:
-platform:time
at:input_datetime.device_start_time
condition:
condition:and
conditions:
-condition:time
after:'00:00'
before:'04:00'
action:
-service:climate.set_temperature
data:
temperature:24
target:
entity_id:climate.ac_12494102
mode:single
The code without timing conditions are available from the blog post link above, so I’m not writing it here, although you can check my full automations.yaml from my GitHub repo – not that I expect it to help anyone or to be perfect, but there it is. Then next thing is to stop the increased heating. To be noted, I constantly work on my automations, so the code in repo does not necessarily reflect what I have demonstrated here.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Set temp to 20C at end of cheap hours
- id:'1663399614821'
alias:Hallway AC temp to20
description:'Cheap energy end time set temp to 20'
trigger:
-platform:time
at:input_datetime.device_end_time
condition:
condition:and
conditions:
-condition:time
after:'03:00'
before:'06:00'
action:
-service:climate.set_temperature
data:
temperature:20
target:
entity_id:climate.ac_12494102
mode:single
I didn’t have time conditions there as time of writing this, but I added them later once I had verified everything works correctly. With Home Assistant it’s better to build things gradually. Then you know easier what does not work and what does.
I also wanted to have things like: If electricity is more expensive than 15c/kWh, decrease heating by 1C:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# If SPOT price is above average let's set heating 1C lower
- id:hallway_ac_fan_expensive_spot
alias:If spot price above average cents set heat 1C lower
description:''
trigger:
-platform:numeric_state
entity_id:sensor.nordpool_kwh_fi_eur_3_10_024
above:sensor.energy_spot_average_price
condition:
condition:and
conditions:
-condition:time
after:'08:00'
before:'22:00'
action:
-service:climate.set_temperature
data:
temperature:"{{ state_attr('climate.ac_12494102', 'temperature') - 1 }}"# Decrease temperature by 1 degree
target:
entity_id:climate.ac_12494102
mode:single
The above is partly written by ChatGPT, but it typically generates code, which needs a lot of tweaking to get it to work for real, but some of it is usable.
I also often turn heater off when outside is a bit warmer and don’t necessarily remember to put it on before going to sleep. At least in theory this could lead to situation where it gets really cold at night, and then the heater is off when temperature is way below 0C. Then one should really not turn it on anymore before it gets warmer, since it decreases the life of the outside unit some what. If not significantly even.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# If outdoor temp is below 1C turn on hallway AC
- id:hallway_ac_fan_on_low_temp
alias:If temp below 1 set on
description:''
trigger:
-platform:numeric_state
entity_id:sensor.ac_12488762_outdoor_temperature
below:1
condition:[]
action:
-service:climate.turn_on
target:
entity_id:climate.ac_12494102
mode:single
Expanding the ideas
Above was just first step though. I wanted to have more. Simple things though. I struggled a day with getting my next idea to work. The idea is simple:
Increase heat, when spot price is above daily average.
Decrease heat, when spot price is below daily average.
I had everything working with fixed values. But daily average spot price varies a lot, so I’m not ok with fixed value. I tried to use something like state_attr('sensor.nordpool_kwh_fi_eur_3_10_024', 'average'). Looks valid to me, but when I tried to use it, it just didn’t work. I tried to “cast” since I always got error “could not convert string to float” no matter what I trid.
Then I figured out just by myself with no Github Copilot, that if I put above to sensors.yaml and create a sensor having the daily average, I might be able to use that. Bingo!
Above I have created sensor: sensor.energy_spot_average_price on sensors.yaml. That I can use on automations.yaml as shown below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# If outdoor temp is below 1C turn on hallway AC
- id:hallway_ac_fan_on_low_temp
alias:If temp below 1 set on
description:''
trigger:
-platform:numeric_state
entity_id:sensor.ac_12488762_outdoor_temperature
below:1
condition:[]
action:
-service:climate.turn_on
target:
entity_id:climate.ac_12494102
mode:single
Since I’m increasing heat above I want to do it only when it’s relatively cold outside. Also I want to do it only during day, when the prior cheapest prices logic is not active. That is why I have set this to do following:
Between 10am and 5pm:
When outside temperature is below +2C and spot price is below daily average:
Lower the heat on Hallway AC by 1 degree celcius
Then I have another entry for decreasing the heat, when spot price goes above daily average. For that I don’t use the requirement for outside temperature, since if it’s warmer than that, I’m always ok to decrease the temperature.
Purpose
The goal for me is to heat a bit more when electricity is cheaper and then heat a bit less when it’s more expensive. Air is not very good on preserving the heat, but it does it a bit. Also, when I go to sleep, I don’t need to heat. My house colder at least till midnight since there’s almost no heating. The after midnight there’s typically the cheapest hours in hand and my system starts to overheat a bit. Pretty normal pattern is, that when I wake up, the electricity price starts to go up during the normal morning hours when other people wake up as well. My heating system isn’t really needed by then and the temperature starts going down gradually till it is needed gain.
Rest of the day my system follows the strategy to lower heat slightly if price goes above average and heat a bit more when it the price goes below average
This will optimize the heating the way, that most of the time the average price I pay for electricity is bit lower than the average spot price, which is my intention.
Below pictures shows, how the heating takes in place at midnight. The stops at 4am. Next hike is around 6am, when the upstairs heat pump in bedroom is turned on after waking up. The bedroom heating is never on during night and most of the automation is only for Hallway AC.
The yaml code needed
The examples here are pretty much copy/pasted from Toni’s blog post so credits to him.
configuration.yaml
Home Assistant needs a configuration file configuration.yaml and there you need following to get the cheapest hours utilized.
1
2
3
4
5
6
7
8
9
10
11
12
13
# Helper to keep the start time
input_datetime:
device_start_time:
name:Device Start Time
has_time:true
has_date:false
device_end_time:
name:Device End Time
has_time:true
has_date:false
# Include automations.yaml and sensors.yaml
automation:!include automations.yaml
sensor:!include sensors.yaml
sensors.yaml
On sensors.yaml you need following. Note that sensor.nordpool_kwh_fi_eur_3_10_024 must be replaced with the sensor you have for Nord Pool integration.
{%- for i in range(firstHour + numberOfSequentialHours,lastHour+1) -%}
{%- set ns.counter = 0.0 -%}
{%- for j in range(i-numberOfSequentialHours,i) -%}
{%- set ns.counter = ns.counter + state_attr('sensor.nordpool_kwh_fi_eur_3_10_024','tomorrow')[j]-%}
{%- endfor -%}
{%- set ns.list = ns.list + [ns.counter]-%}
{%- if ns.counter < ns.cheapestPrice -%}
{%- set ns.cheapestPrice = ns.counter -%}
{%- set ns.cheapestHour = today_at("00:00") + timedelta( hours = (24 + i - numberOfSequentialHours)) -%}
{%- endif -%}
{%- endfor -%}
{{ns.cheapestHour }}
{%- set ns.cheapestPrice = ns.cheapestPrice / numberOfSequentialHours -%}
{%- endif -%}
automations.yaml
Now Here are the triggers I have created in automations.yaml. I have three triggers for pumping up the heat with each one different action for cheap hours. Combining actions with one trigger seem not to work, or I don’t know correct syntax. I decrease the heat after four hours, but since I don’t need to stop heater, when the heating gets decreased. I have only two actions.
First I need to create the input_date times to use later:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# Set device start time: Needs cheapest_hours_energy_tomorrow in sensor.yaml
Home Assistant is useful tool to make some simple home automations. Obviously getting the heat pump itself have saved me plenty on electricity bills, but Home Assistant takes me one step further.
Although Home Assistant does provide nice GUI for creating schedules, I do prefer editing the text based yaml files. yaml itself is error prone format and for that good editor is a must. My choice of editor has been vim for last 20 years at least and I see no reason to switch away from it. Although I have tried to switch to Eclipse, Pycharm, VS Code – yet I always go back to vim. I even tried neovim but couldn’t find any difference compared to vim (I do not use lua).
When I found Github Pilot plugin for vim I found it to be a game changer. Not only for writing Python and Azure Pipelines with yaml, but especially for Home Assistant configuration yaml files. I also feel GitHub Copilot extremely addictive. The way it provides suggestions makes me chuckle once in a while and I really miss it almost everywhere – almost. It really would need to write my commit messages with vim fugitive. Feature suggestion for Tim.
Jag ville läsa den här boken på svenska, även om mina kunskaper i svenska är ganska begränsade. Jag tänkte att det skulle vara en utmärkt möjlighet att öva på språket. Jag studerade svenska i skolan för mer än trettio år sedan.
Berättelsen handlar om livet för en finlandssvensk författare, från hans barndom till att han blir 55 år. Den skildrar hans första kärlek och deras liv – både tillsammans och isär.
Den tar även upp författarens vänner och deras liv i Helsingfors under 60-talet fram till idag. Det finns många detaljer om Helsingfors skärgård och även olika platser i staden som är kära för mig.
Att läsa den här boken tog mig lite längre tid än jag hade förväntat mig. Men det var min första bok på finlandssvenska, och den var på 475 sidor.
Den här också min första bokrecensionen på svenska
I was a bit sceptic about this book. I have read Krugman’s NYTimes blog posts and although I like them, I didn’t expect they would carry a book. But this is well organised and has a lot of additional essays which makes it actually very interesting book to read. Although most of the book is about US economy and welfare including health care, it does go beyond US and covers the economic issues EU has as well.
I would have given actually 5 starts, but there’s some mistakes. This is understandable, since it is mostly collection of blog posts author published in NYTimes after all. But hey, when Krugman covers EU problems and euro as it’s currency, it is true, that Island has it’s own currency, but it’s not EU country and it’s economical issues were way different than anywhere in EU countries. Also, as a Finn, ahem, Ericsson is Swedish company, we here in Finland have Nokia.
Although like said, the focus is mostly focus US. I have lived a decade in Canada and rest of my life in Finland and still found book highly interesting and it’s findings fitting very well for European economic policies as well. Krugman seems to have very European way of thinking about welfare and health care. He calls it social democratic instead of socialism. This is one thing where he goes a bit off. Rightist parties in Europe mostly do support social security and health care; it’s not only social democrats.
I decided to check this book after watching the movie made from it: “Leave No Trace”. I was wondering if it was a good decision, since I already knew how it is going to end, right? Well, no, the book is independent from the movie. No harm reading the book after watching the movie.
It’s interesting book and creates weird psychological tense towards the end. Is anything there as the reader expects things to be?
This is book mostly about addiction, insecurity, fame and Matthew Perry. It’s less about lovers and even less about Friends, TV show. On many of reviews poor editing is mentioned. Not sure if some of the reason for critic has been fixed on up to date edition or is my English just so poor that I just don’t notice any of that.
I wonder how much easier Matty’s life would have been without all the money and fame. I assume it’s easier to relapse time after the time when you have endless amount of money to spend on rehabs, medication and health care. What ever it is it seems for an outsider, that too much of everything has pretty much ruined Matty’s life, health and relationships.
But he seems to be some what ok now. He is still relatively young and he hasn’t been able to toss out all of his money. I didn’t get feeling he has succeeded in his life though. He has been in number 1 TV Show and number 1 movie same time and earned insane amount of money. Some how any of that does’t seem to make him feel he has succeeded on anything. His life is constant battle against his demons and health issues.
I’m not sure if there’s anything to learn from this book. Except addiction is terrible disease and having too much money certainly does not make it any easier. When you have so much money that you cannot spent any significant amount of it to drugs, pills and alcohol and you can afford to spend $7 million to rehabs alone money obviously does not solve anything.
I didn’t borrow this book to read about Friends, but about Matty’s addiction. It was somewhat entertaining (the way real life Chandler, Matty himself, puts it) and somewhat shocking. I hope Matty gets his shit together and can live happier life now.
Eittämättä yksi merkittävimpiä taloustieteen kirjoja 2000-luvulla. Oma kiinnostukseni heräsi erityisesti Björn Wahlroosin “Talouden kymmenen tuhoisinta ajatusta” -kirjassaan esittämän kritiikin vuoksi. Nalle on toki taitava talousmies ja omaa kunnioitettavan akateemisen historian, mutta tällä kertaa kritiikki meni pieleen. Hän selkeästikin oli lukenut kirjan hyvin pinnallisesti, ja on täysin jäävi arvostelemaan kirjaa, jonka pääajatus on estää koroillaeläjien yhteiskuntien synty.
Kirjan pääajatus on, että kun pääoman tuoton kasvu ylittää kansantulon kasvun, epäyhtälö r > g, pääomaa alkaa pitkän ajan kuluessa kertymään yksityisille henkilöille, instituutioille ja (öljy)maille niin paljon, että syntyy samanlainen koroillaeläjien yhteiskunta, kuin ennen maailmansotia vielä oli olemassa.
Nallehan on itse omaisuutensa luonut taitavien ja onnekkaiden sijoitusten kautta. Hän on silti loistava esimerkki siitä, mitä kirja tarkoittaa koroillaeläjillä. Jotkut luovat valtavan omaisuuden omalla työllään. Toiset saavat sen perinnöllä tai pääsevät osallisiksi naimalla koroillaeläjän.
Kun on tarpeeksi omaisuutta, niin sen vuotuiset tuotot ovat sitä verta suuret, että vaikka tuotoista kuluttaisi vuodessa yli 100 kertaa mediaanipalkan verran, niin pystyisi edelleen sijoittamaan uudelleen niin paljon, että pääoma jatkaa kasvamistaan yhä kiihtyvässä tahdissa.
Tämähän ei Pikettyn mukaan ole vielä ongelma. Ongelma on se, että pääoman kasvaessa tarpeeksi suureksi, se jatkaa kasvamistaan loputtomasti keskittyen hyvin harvoille, ja sen jälkeen syntyy ihmisryhmä, joille työllä ei ole enää mitään merkitystä, koska työstä ei koskaan voi saada vastaavia tuottoja kuin valtavasta omaisuudesta. Enemmistölle ihmisistä taas ei jää kansantalouden kasvusta juuri mitään käteen, kun se keskittyy superrikkaille. Epäyhtälö r > g. Tällainen tilanne oli vielä ennen maailmansotia. Edelleenkin epäyhtälö r > g pitää paikkansa, ja Pikettyn pahin skenaario on, että jossain vaiheessa luisumme koroillaeläjien maailmaan. Hän ei väitä, että se on vääjäämätöntä, mutta mahdollista.
Koska nykyaikana ihmisten elinikä on jo niin korkea, että perintö tulee varsin myöhään, kannattaa lapsilleen antaa valtavia lahjoituksia jo huomattavasti varhaisemmin. Tämä on tietysti sitä kannattavampaa, mitä alhaisempi lahja- ja perintövero on. Kukahan suomalainen tästä tulee mieleen?
Pikettyn kritiikki ei siis sinällään keskity valtavien omaisuuksien keräämiseen omalla työllään, vaan siihen, että syntyy sukuja ja instituutioita, joiden ja joissa ei enää koskaan tarvitse tehdä tuottavaa työtä tai toimintoja. Työn tai muun tuottavan toiminnan sijaan on kannattavampaa elää perimänsä pääoman koroilla tai yrittää edes päästä naimalla tällaiseen sukuun.
Piketty kritisoi myös superjohtajien valtavia tuloja, jotka mm. Yhdysvalloissa aina 1970-lukuun asti estettiin yhdellä maailman kovimmista progressioista, kunnes tätä alettiin pikkuhiljaa laskemaan ja päästiin alhaisimpaan tasoon Reaganin kaudella. Pikettyn huoli sinällään valtavien palkkojen suhteen ei ole kertymättä jääneet verot, koska suurituloisia, puhumme useista miljoonista, on sen verran vähän, vaan yhteiskunnallisen eriarvoisuuden kasvaminen.
Piketty nostaa esiin yhteiskuntien nykyisen velkaantumisasteen, joka lienee ongelma, jota taloustieteilijät eivät yleisesti ottaen kiistä. Velat ovat kuitenkin huomattavasti pienempiä, kuin yksityinen varallisuus. Euroopan maista suurin yksityinen varallisuus on Italialla ja Espanjalla. Nämä ovat myös yhdet Euroopan velkaantuneimmista maista. Euroopan velat muutoinkin alittavat reilusti yksityisen omaisuuden. Euroopan yksityinen omaisuus on maailman suurin ja esimerkiksi 20 kertaa suurempi, kuin Kiinan omistamat ulkomaiset varat. Kiina ei siis ihan heti ole ostamassa koko maailma.
Ratkaisuksi siihen, ettei koroillaeläjien yhteiskuntia synny uudelleen, eli paluuseen aikaan ennen maailmansotia, sekä velkaantumiseen, Piketty tarjoaa globaalia progressiivista pääomaveroa. Toki hän itsekin myöntää, että ajatus on sangen utopistinen, minkä Nallekin omassa kritiikissään huomioi. Utopistinen ajatuskin voi olla silti toimiva.
Piketty huomauttaa, että olihan valuutta ilman kotimaatakin utopistinen ajatus, mutta silti euro syntyi. Piketty tosin ei näe eurossa oikein mitään hyvää, toisin kuin ehdotuksessaan globaalisista progressiivisesta pääomaverosta.
Piketty ei väitä aineistonsa olevan täydellistä, mutta se kattaa valtavan pitkän aikajanan aina 1700-luvulta nykypäivään. Siksi hänen analyysinsä lienee melko paikkansa pitävää, vaikka epävarmuustekijöitä tietysti on.
Onko hänen tarjoamansa ratkaisu utopiaa, vai toteutettavissa; sitä en tiedä. Yhdysvaltojen toteuttama Foreign Account Tax Compliance Act (FATCA) tuntuu joka tapauksessa toimivan melko tehokkaasti, ja harva yhdysvaltalainen pääsee veroja pakoon muuten, kuin luopumalla kansalaisuudesta. Siinä mielessä vastaavan painostuksen alla globaali progressiivinen pääomaverokin lienisi toteustuskelpoinen, jos valtiot pääsisivät siitä yhteisymmärrykseen. Jälkimmäinen tosin lienee utopiaa. Edes Euroopan maiden välillä ei ole kyetty toteuttamaan FATCA:n kaltaista järjestelmää.
Yhtäkaikki, kirja on erittäin mielenkiintoinen katsaus tulo- ja varallisuuseroihin ja paikoin sangen leppoisaa luettavaa viitteineen kaunokirjallisuuteen.