
Netezza is designed with simplicity in mind. You can get it up and running in hours rather than weeks. When you follow the basic rules, 99 percent of your applications and queries can perform well. There are six things you should keep in mind while designing your databases and setting up maintenance tasks:
- Distribution
- Data types
- Statistics
- Zone maps
- Data organization
- Groom
When you have taken care of the these things, you shouldn’t have any major issues with performance. However, if you do have issues, how do you find them? Follow these five steps, which can help you to find and possibly fix the performance issues on your appliance.
1. Use IBM Netezza Performance Portal and the query history database
The IBM Netezza Performance Portal is an excellent tool for making sure you have everything in place, and if you don’t it will help you to identify any issues. It provides an excellent front end to the query history database and it is able to connect the appliance performance history with your query history.
Netezza Performance Portal and its installation guide are available for download from IBM Fix Central. The installation is fairly simple. Please refer to the “IBM Netezza Performance Portal User’s Guide” (which is included in the download) for installing and configuring both Netezza Performance Portal and the query history database.
2. Check the server load and resources
One of the greatest things about Netezza Performance Portal is its ability to monitor one or more Netezza systems and their resource usage. From the nice graphical user interface (GUI) you can easily identify performance peaks. Then, if you see any changes in trend, you can drill down and take a closer look by using your mouse pointer to click where the change begins and ends. You can repeat this as many times as you want. After zooming in on the period of time you are interested in, you can click the “Jump to History” button to see which queries were running during that time slot. But first you will need to choose the host you are interested in, as this will populate the “Submit Time” and “Finish Time” fields in the query history view.
3. Identify the problematic queries
Identifying problematic queries is, of course, easier said than done. Basically, there are three different types of long-lasting queries that usually require a closer look:
- Queries that take a long time to finish because they need to access a lot of data.
- Queries that take long time to finish because the query is not optimal.
- Queries that take a long time to finish because the database design is not optimal.
When you first look at your queries, they probably just look like long-lasting queries. However, if you know your data and your queries, you might be able to place at least some of them in the first class I mentioned (queries that naturally take a long time to finish because of large amounts of data). What I usually do myself, after I have zoomed in on a performance peak or otherwise interesting period from the Netezza Performance Portal monitoring view, is sort the queries based on their “Query Duration.” I simply list the queries in descending order and then look at the “Query Text.”
When you have selected the interesting query, you can perform various actions with Netezza Performance Portal, including the following:
- You can right-click the query and check the “Identical Query Trend Chart.” This will give you an idea of the variation in duration for identical queries over time. For instance, if the system is overwhelmed by concurrently running workloads, it is obvious that a query will not run as fast as it normally would. If you notice that a query took longer than normal to run, you should check what else was running on the system at that time.
- If it really took longer to run than is typical, you can check the “Query/Plan Activity Chart.” This will give you a nice graphical view of all the queries running concurrently on the system, which could be affecting the duration of the query you were interested in.
- You can check if the statistics are up to date on tables related to the query, and you can even update the statistics thorough Netezza Performance Portal if they are outdated.You can also check encumbrance. There might have been, for instance, loads or aborted ad hoc queries running on the system that negatively affected the system performance. I have once identified the latter to be the case for why highly-prioritized extract, transform and load (ETL) tasks did not finish in time. Since the queries were aborted, they were not seen in the Query/Plan Activity Chart, but rather on the encumbrance view.
Picture 1: Identical Query Trend Chart
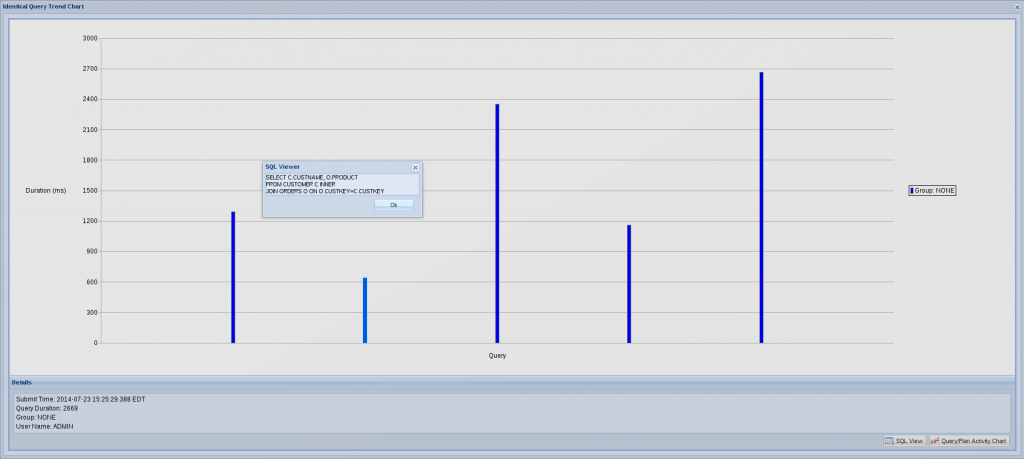
4. Check the query plan
You can check the query plan directly from Netezza Performance Portal and that’s not a bad choice. However, what I usually do is check only the plan ID. You can find this from one of the columns when you are listing the queries on the query history view. I then take the plan ID, log in to the appliance and use nz_plan to take a closer look at the query. One advantage of nz_plan is that it lists the interesting snippets early in the file. Another attractive feature is that it rewrites the query very nicely in a readable format.
That said, you can still use the other techniques available to produce the query plan, including the one available directly through Netezza Performance Portal.
Picture 2: Query Plan generated with nz_plan
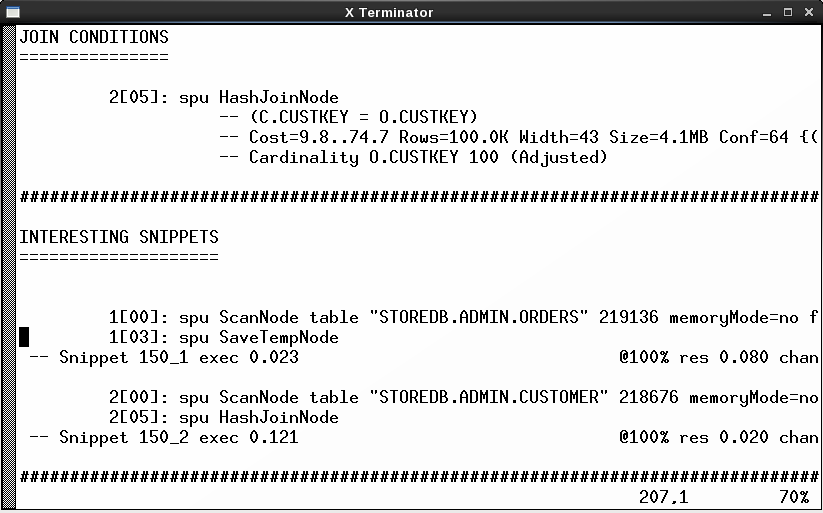
5. Check the distribution keys and change them if needed
Now that you have the query plan, one of the first things you can check from there are the distribution keys for the tables the query is accessing. Are they what you assumed they were? Are there re-distributions—single or double? If you see something like “1[03]:spu DownloadTableNode distribute into link 2147484337” you know that the table is distributed. If you assumed it isn’t, then you should check the distribution keys again.
Check how it works now when there are no issues
Don’t wait until you have issues. Familiarize yourself on how to monitor performance issues before you have performance issues. If you don’t already have Netezza Performance Portal, install and deploy it. Try and test how nz_plan utility works. Read the query plans. By doing this, you will be ahead of the game and ready to tackle any upcoming issues.
If you have any questions or suggestions related to query performance tuning, please leave a comment. You can also follow me on Twitter @TVaattanen to discuss more about Netezza.
 |  |  |






{kind=link}